Research
Active Collaborations
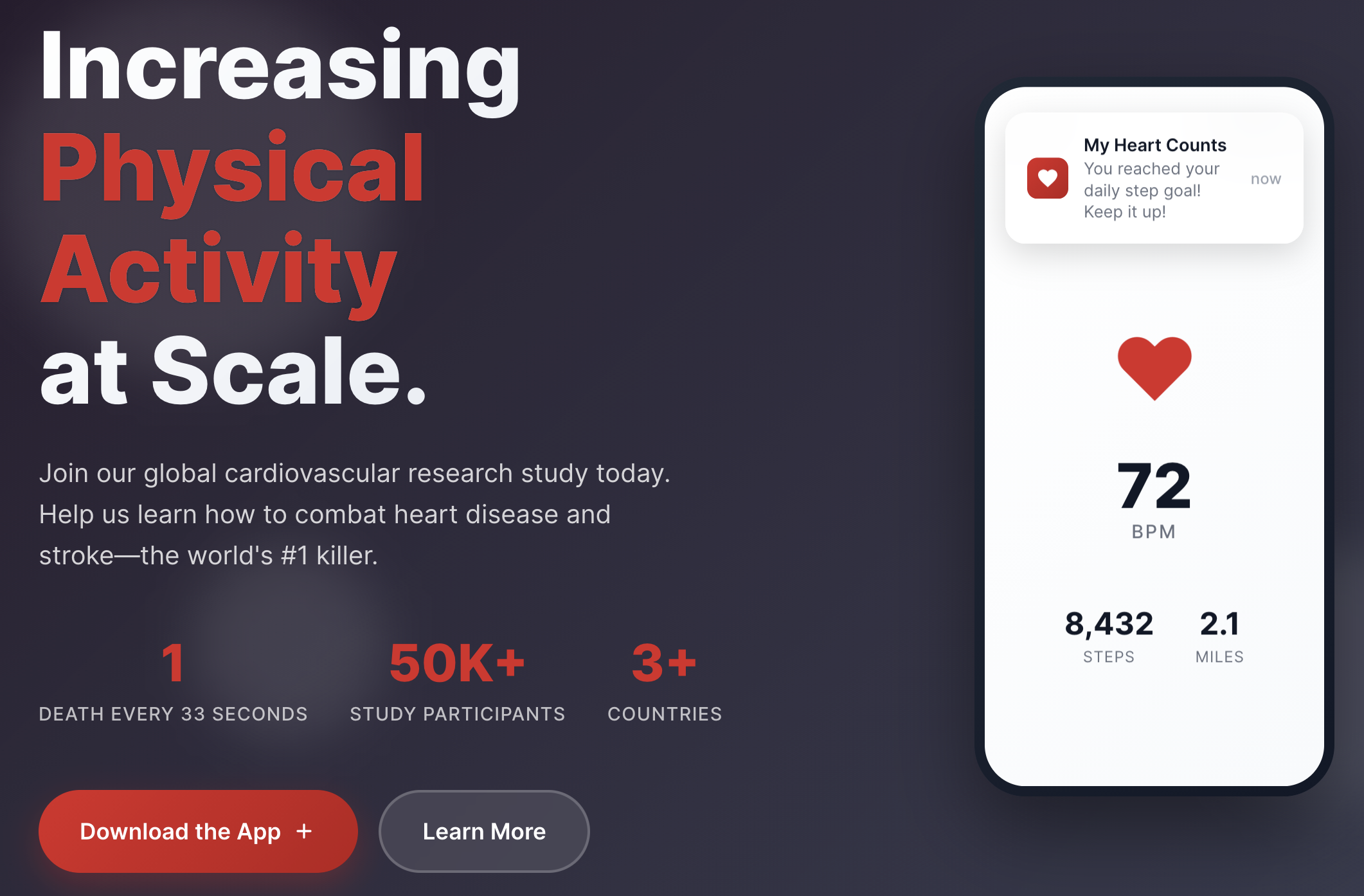
Mobile Health Coaching to Increase Physical Activity
My group is collaborating with medical researchers at Imperial and Stanford University on My Heart Counts, a global cardiovascular research study app with over 50,000 users. Our focus is developing a LLM-based digital health coach to deliver personalized intervention messages aimed at increasing physical activity. The intervention will use reinforcement learning to adapt and personalize messaging over time. Further work involves developing novel machine learning methods for the large-scale, passively collected wearable sensor data from the app.
Papers
- Health AIOpenMHC: Accelerating the Science of Wearable Foundation ModelsNarayan Schuetz, Yuze Bai, Lianggang Pan, Edgar Eggert, Favour Nerrise, Juan Delgado-SanMartin, Max Rosenblattl, Milana Gurbanova, Mohammad Asadi, Anders Johnson, Paul Schmiedmayer, Dennis Wang, Allan Lawrie, Daniel Seung Kim, Xin Liu, Akshay Paruchuri, Ehsan Adeli, Euan Ashley*, and Kelly W. Zhang*Under submission, 2026
Mobile and wearable devices offer an unprecedented opportunity for continuous, passive health monitoring and active health coaching. However, the largest wearable datasets are not publicly available for research, and leading wearable foundation models trained on such datasets are rarely open-weight or come with reproducible training code. To accelerate open science in wearable health, we release \boOpenMyHeartCounts (OpenMHC), the largest and most comprehensive open-access wearable health dataset to date, alongside open-source implementations of recent wearable foundation models. \openmhc, derived from over a decade of data collected through the My Heart Counts study app, includes >60 million hours of wearable data across 19 sensor channels (e.g., step count, heart rate, sleep, workouts) and up to 169 linked variables, including health, lifestyle, mood, and behavior from 11,894 consenting participants. Furthermore, we introduce a unified, open benchmark that enables standardized comparison of wearable health models across three tracks: health and behavior downstream prediction, multivariate data imputation, and time-series forecasting. We benchmark classical methods alongside recent wearable and multivariate time series foundation models. By open-sourcing data, code, and model weights at this unprecedented scale, we aim to democratize wearable health AI research and enable the community to drive open progress in this domain.
@article{openMHC2026, title = {OpenMHC: Accelerating the Science of Wearable Foundation Models}, author = {Schuetz, Narayan and Bai, Yuze and Pan, Lianggang and Eggert, Edgar and Nerrise, Favour and Delgado-SanMartin, Juan and Rosenblattl, Max and Gurbanova, Milana and Asadi, Mohammad and Johnson, Anders and Schmiedmayer, Paul and Wang, Dennis and Lawrie, Allan and Kim, Daniel Seung and Liu, Xin and Paruchuri, Akshay and Adeli, Ehsan and Ashley, Euan and Zhang, Kelly W.}, journal = {Under submission}, year = {2026}, } - Bandits/RLBandit Simulation for Average Reward InferenceSamya Praharaj, Chih-Yu Chang, Koulik Khamaru, and Kelly W. ZhangUnder submission, 2026
Multi-arm bandit algorithms are increasingly used in online platforms, clinical trials, and social science experiments, but valid statistical inference on their performance remains an open challenge. After deploying bandits, a natural question is whether one can construct a confidence interval for its mean reward and assess whether it reliably outperforms a baseline policy. The total reward achieved in any single bandit deployment is random, and deploying a bandit twice on the same population typically yields different reward trajectories due to stochastic rewards. Standard statistical inference methods cannot be used because bandit algorithms introduce complex dependencies in the collected data, which violate the i.i.d. assumption underlying many classical approaches. Moreover, existing inference methods for adaptively collected data only apply to estimands that do not depend on the data-collection algorithm (such as the mean reward under a fixed action). We propose Bandit Simulation for Inference (BSI), a framework that fits a simulator of the bandit environment from observed data–either on-policy or off-policy–and uses it to estimate the mean reward under any evaluation policy, including adaptive blackbox algorithms. BSI formally propagates uncertainty in the estimated simulator parameters into the confidence interval construction. Furthermore, for BSI to be valid, it requires only weak exploration assumptions on the behavior policy and avoids importance weighting. We prove that BSI yields asymptotically valid confidence intervals, and demonstrate empirically that it maintains nominal coverage in settings where standard off-policy evaluation methods fail.
@article{banditSimulationInference2026, title = {Bandit Simulation for Average Reward Inference}, author = {Praharaj, Samya and Chang, Chih-Yu and Khamaru, Koulik and Zhang, Kelly W.}, journal = {Under submission}, year = {2026}, } - Health AIDesign and Rationale of the My Heart Counts Cardiovascular Health Study: a Large-Scale, Fully Digital Biobank, and Randomized Trial of Large Language Model-Driven Coaching of Physical ActivityPaul Schmiedmayer, Anders Johnson, Narayan Schuetz, Lukas Kollmer, Paul Goldschmidt, Juan Delgado-SanMartin, Kelly W. Zhang, Sriya Mantena, Alex Tolas, Samuel Montalvo, Mariana Ramirez-Posada, Jack W. O’Sullivan, Marily Oppezzo, Abby C King, Fatima Rodriguez, Euan Ashley, Allan Lawrie, and Daniel Seung KimAmerican Journal of Preventive Cardiology, 2026
Background: Cardiovascular disease remains the leading cause of global morbidity and mortality. The original My Heart Counts smartphone application demonstrated the feasibility of large-scale, fully digital recruitment and trial conduct, but was limited by platform exclusivity and the need for human experts to create text-based behavioral interventions. Methods: The next-generation My Heart Counts smartphone application is a prospective, observational cohort study with an embedded randomized crossover trial, evaluating personalized text-based coaching prompts, available in both English and Spanish. All study and trial operations will be conducted via the My Heart Counts smartphone application, re-designed using the open-source Stanford Spezi framework to support iOS, with a planned Android release in 2027. The target enrollment is N=15,000 adults across the United States and United Kingdom. The study establishes a comprehensive digital biobank by synthesizing passive mobile health data (steps, flights climbed, heart rate, sleep, workouts), raw sensor data (e.g., accelerometry), longitudinal clinical surveys, active tasks (6-minute walk test and 12-minute Cooper run test), electrocardiograms (ECG), and electronic health record (EHR) data integrated via HL7 FHIR protocols. The embedded trial evaluates the effect of text-based coaching prompts generated by a large language model (LLM) grounded in the Transtheoretical Model of Change on daily physical activity, as compared to generic prompts. Planned Analysis: The primary endpoint of the randomized crossover trial is change in daily step count between LLM-driven and generic text-based intervention arms, analyzed using mixed-effects models. Secondary endpoints include change in mean active minutes and calorie burn over each intervention week. Other analyses include the changes in submaximal (6-minute walk test) and maximal (Cooper 12-minute run test) cardiorespiratory fitness, changes to sensor-derived biomarkers (e.g., sleep quality, resting heart rate, and heart rate variability), and association of sensor-derived biomarkers with EHR-confirmed clinical outcomes. Conclusions: By utilizing autonomous, LLM-driven coaching, modular software design, and cross-platform accessibility, our smartphone application-based study will provide a scalable model for inclusive and decentralized preventive care of patients with cardiovascular disease. Trial Status: Recruitment commenced in March 2026 and is ongoing.
@article{MHC2026, title = {Design and Rationale of the My Heart Counts Cardiovascular Health Study: a Large-Scale, Fully Digital Biobank, and Randomized Trial of Large Language Model-Driven Coaching of Physical Activity}, author = {Schmiedmayer, Paul and Johnson, Anders and Schuetz, Narayan and Kollmer, Lukas and Goldschmidt, Paul and Delgado-SanMartin, Juan and Zhang, Kelly W. and Mantena, Sriya and Tolas, Alex and Montalvo, Samuel and Ramirez-Posada, Mariana and O’Sullivan, Jack W. and Oppezzo, Marily and King, Abby C and Rodriguez, Fatima and Ashley, Euan and Lawrie, Allan and Kim, Daniel Seung}, journal = {American Journal of Preventive Cardiology}, year = {2026}, } - MLTabular Foundation Models Can Do Survival AnalysisDa In Kim, Wei Siang Lai, and Kelly W. ZhangUnder submission, 2026
While tabular foundation models have achieved remarkable success in classification and regression, adapting them to model time-to-event outcomes for survival analysis is non-trivial due to right-censoring, where data observations may end before the event occurs. We develop a classification-based framework that reformulates both static and dynamic survival analysis as a series of binary classification problems by discretizing event times. Censored observations are naturally handled as examples with missing labels at certain time points. This classification formulation enables existing tabular foundation models to perform survival analysis through in-context learning without explicit training. We prove that under standard censoring assumptions, minimizing our binary classification loss recovers the true survival probabilities as the training set size increases. We demonstrate through evaluation across 53 real-world datasets that off-the-shelf tabular foundation models with this classification formulation outperform classical and deep learning baselines on average over multiple survival metrics.
@article{TFMsurvival2026, title = {Tabular Foundation Models Can Do Survival Analysis}, author = {Kim, Da In and Lai, Wei Siang and Zhang, Kelly W.}, journal = {Under submission}, year = {2026}, } - Bandits/RLStatistical Reinforcement Learning in the Real World: A Survey of Challenges and Future DirectionsAsim H. Gazi, Yongyi Guo, Daiqi Gao, Ziping Xu, Kelly W. Zhang, and Susan A. MurphyMajor Revision at Annals of Applied Statistics, 2026
Reinforcement learning (RL) has achieved remarkable success in real-world decision-making across diverse domains, including gaming, robotics, online advertising, public health, and natural language processing. Despite these advances, a substantial gap remains between RL research and its deployment in many practical settings. Two recurring challenges often underlie this gap. First, many settings offer limited opportunity for the agent to interact extensively with the target environment due to practical constraints. Second, many target environments often undergo substantial changes, requiring redesign and redeployment of RL systems (e.g., advancements in science and technology that change the landscape of healthcare delivery). Addressing these challenges and bridging the gap between basic research and application requires theory and methodology that directly inform the design, implementation, and continual improvement of RL systems in real-world settings. In this paper, we frame the application of RL in practice as a three-component process: (i) online learning and optimization during deployment, (ii) post- or between-deployment offline analyses, and (iii) repeated cycles of deployment and redeployment to continually improve the RL system. We provide a narrative review of recent advances in statistical RL that address these components, including methods for maximizing data utility for between-deployment inference, enhancing sample efficiency for online learning within-deployment, and designing sequences of deployments for continual improvement. We also outline future research directions in statistical RL that are use-inspired – aiming for impactful application of RL in practice.
@article{statRL2026, title = {Statistical Reinforcement Learning in the Real World: A Survey of Challenges and Future Directions}, author = {Gazi, Asim H. and Guo, Yongyi and Gao, Daiqi and Xu, Ziping and Zhang, Kelly W. and Murphy, Susan A.}, journal = {Major Revision at Annals of Applied Statistics}, year = {2026}, } - Health AILearning Health Systems provide a glide path to safe landing for AI in healthVasa Curcin, Brendan Delaney, Ahmad Alkhatib, Neil Cockburn, Olivia Dann, Olga Kostopoulou, Daniel Leightley, Matthew Maddocks, Sanjay Modgil, Krishnarajah Nirantharakumar, Philip Scott, Ingrid Wolfe, Kelly W. Zhang, and Charles FriedmanArtificial Intelligence in Medicine, 2026
Artificial Intelligence (AI) holds significant promise for healthcare but often struggles to transition from development to clinical integration. This paper argues that Learning Health Systems (LHS)—socio-technical ecosystems designed for continuous data-driven improvement—provide a potential “glide path” for safe, sustainable AI deployment. Just as modern aviation depends on instrument landing systems, the safe and effective integration of AI into healthcare requires the socio-technical infrastructure of LHSs, that enable iterative development and monitoring of AI tools, integrating clinical, technical, and ethical considerations through stakeholder collaboration. They address key challenges in AI implementation, including model generalizability, workflow integration, and transparency, by embedding co-creation, real-world evaluation, and continuous learning into care processes. Unlike static deployments, LHSs support the dynamic evolution of AI systems, incorporating feedback and recalibration to mitigate performance drift and bias. Moreover, they embed governance and regulatory functions—clarifying accountability, supporting data and model provenance, and upholding FAIR (Findable, Accessible, Interoperable, Reusable) principles. LHSs also promote “human-in-the-loop” safety through structured studies of human-AI interaction and shared decision-making. The paper outlines practical steps to align AI with LHS frameworks, including investment in data infrastructure, continuous model monitoring, and fostering a learning culture. Embedding AI in LHSs transforms implementation from a one-time event into a sustained, evidence-based learning process that aligns innovation with clinical realities, ultimately advancing patient care, health equity, and system resilience. The arguments build on insights from an international workshop hosted in 2025, offering a strategic vision for the future of AI in healthcare.
@article{learningHealthSystems2026, title = {Learning Health Systems provide a glide path to safe landing for AI in health}, author = {Curcin, Vasa and Delaney, Brendan and Alkhatib, Ahmad and Cockburn, Neil and Dann, Olivia and Kostopoulou, Olga and Leightley, Daniel and Maddocks, Matthew and Modgil, Sanjay and Nirantharakumar, Krishnarajah and Scott, Philip and Wolfe, Ingrid and Zhang, Kelly W. and Friedman, Charles}, journal = {Artificial Intelligence in Medicine}, year = {2026}, } - Bandits/RLReproducible workflow for online AI in digital healthSusobhan Ghosh, Bhanu T. Gulapalli, Daiqi Gao, Asim Gazi, Anna Trella, Ziping Xu, Kelly W. Zhang, and Susan A. MurphyPhilosophical Transactions A, 2026
Online artificial intelligence (AI) algorithms are an important component of digital health interventions. These online algorithms are designed to continually learn and improve their performance as streaming data is collected on individuals. Deploying online AI presents a key challenge: balancing adaptability of online AI with reproducibility. Online AI in digital interventions is a rapidly evolving area, driven by advances in algorithms, sensors, software, and devices. Digital health intervention development and deployment is a continuous process, where implementation - including the AI decision-making algorithm - is interspersed with cycles of re-development and optimization. Each deployment informs the next, making iterative deployment a defining characteristic of this field. This iterative nature underscores the importance of reproducibility: data collected across deployments must be accurately stored to have scientific utility, algorithm behavior must be auditable, and results must be comparable over time to facilitate scientific discovery and trustworthy refinement. This paper proposes a reproducible scientific workflow for developing, deploying, and analyzing online AI decision-making algorithms in digital health interventions. Grounded in practical experience from multiple real-world deployments, this workflow addresses key challenges to reproducibility across all phases of the online AI algorithm development life-cycle.
@article{reproducible2026, title = {Reproducible workflow for online AI in digital health}, author = {Ghosh, Susobhan and Gulapalli, Bhanu T. and Gao, Daiqi and Gazi, Asim and Trella, Anna and Xu, Ziping and Zhang, Kelly W. and Murphy, Susan A.}, journal = {Philosophical Transactions A}, year = {2026}, } - Bandits/RLEffective Monitoring of Online Decision-Making Algorithms in Digital Intervention ImplementationAnna L. Trella*, Susobhan Ghosh*, Erin E. Bonar, Lara Coughlin, Finale Doshi-Velez, Yongyi Guo, Pei-Yao Hung, Inbal Nahum-Shani, Vivek Shetty, Maureen Walton, Iris Yan, Kelly W. Zhang, and Susan A. MurphyTo appear in npj Digital Medicine, 2026
Online AI decision-making algorithms are increasingly used by digital interventions to dynamically personalize treatment to individuals. These algorithms determine, in real-time, the delivery of treatment based on accruing data. The objective of this paper is to provide guidelines for enabling effective monitoring of online decision-making algorithms with the goal of (1) safeguarding individuals and (2) ensuring data quality. We elucidate guidelines and discuss our experience in monitoring online decision-making algorithms in two digital intervention clinical trials (Oralytics and MiWaves). Our guidelines include (1) developing fallback methods, pre-specified procedures executed when an issue occurs, and (2) identifying potential issues categorizing them by severity (red, yellow, and green). Across both trials, the monitoring systems detected real-time issues such as out-of-memory issues, database timeout, and failed communication with an external source. Fallback methods prevented participants from not receiving any treatment during the trial and also prevented the use of incorrect data in statistical analyses. These trials provide case studies for how health scientists can build monitoring systems for their digital intervention. Without these algorithm monitoring systems, critical issues would have gone undetected and unresolved. Instead, these monitoring systems safeguarded participants and ensured the quality of the resulting data for updating the intervention and facilitating scientific discovery. These monitoring guidelines and findings give digital intervention teams the confidence to include online decision-making algorithms in digital interventions.
@article{monitoring2026, title = {Effective Monitoring of Online Decision-Making Algorithms in Digital Intervention Implementation}, author = {Trella, Anna L. and Ghosh, Susobhan and Bonar, Erin E. and Coughlin, Lara and Doshi-Velez, Finale and Guo, Yongyi and Hung, Pei-Yao and Nahum-Shani, Inbal and Shetty, Vivek and Walton, Maureen and Yan, Iris and Zhang, Kelly W. and Murphy, Susan A.}, journal = {To appear in npj Digital Medicine}, year = {2026}, } - Bandits/RLImpatient Bandits: Optimizing for the Long-Term Without DelayKelly W. Zhang, Thomas Baldwin-McDonald, Kamil Ciosek, Lucas Maystre, and Daniel RussoTo appear in Journal of Machine Learning (JMLR), 2026
Increasingly, recommender systems are tasked with improving users’ long-term satisfaction. In this context, we study a content exploration task, which we formalize as a bandit problem with delayed rewards. There is an apparent trade-off in choosing the learning signal: waiting for the full reward to become available might take several weeks, slowing the rate of learning, whereas using short-term proxy rewards reflects the actual long-term goal only imperfectly. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Rewards as well as shorter-term surrogate outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that quickly learns to identify content aligned with long-term success using this new predictive model. We prove a regret bound for our algorithm that depends on the Value of Progressive Feedback, an information theoretic metric that captures the quality of short-term leading indicators that are observed prior to the long-term reward. We apply our approach to a podcast recommendation problem, where we seek to recommend shows that users engage with repeatedly over two months. We empirically validate that our approach significantly outperforms methods that optimize for short-term proxies or rely solely on delayed rewards, as demonstrated by an A/B test in a recommendation system that serves hundreds of millions of users.
@article{impatientBandits2026, title = {Impatient Bandits: Optimizing for the Long-Term Without Delay}, author = {Zhang, Kelly W. and Baldwin-McDonald, Thomas and Ciosek, Kamil and Maystre, Lucas and Russo, Daniel}, journal = {To appear in Journal of Machine Learning (JMLR)}, year = {2026}, } - Statistical InferenceReplicable Bandits for Digital Health InterventionsKelly W. Zhang, Nowell Closser, Anna L. Trella, and Susan A. MurphyStatistical Science, 2025
Adaptive treatment assignment algorithms, such as bandit and reinforcement learning algorithms, are increasingly used in digital health intervention clinical trials. Causal inference and related data analyses are critical for evaluating digital health interventions, deciding how to refine the intervention, and deciding whether to roll-out the intervention more broadly. However the replicability of these analyses has received relatively little attention. This work investigates the replicability of statistical analyses from trials deploying adaptive treatment assignment algorithms. We demonstrate that many standard statistical estimators can be inconsistent and fail to be replicable across repetitions of the clinical trial, even as the sample size grows large. We show that this non-replicability is intimately related to properties of the adaptive algorithm itself. We introduce a formal definition of a "replicable bandit algorithm" and prove that under such algorithms, a wide variety of common statistical analyses are guaranteed to be consistent. We present both theoretical results and simulation studies based on a mobile health oral health self-care intervention. Our findings underscore the importance of designing adaptive algorithms with replicability in mind, especially for settings like digital health where deployment decisions rely heavily on replicated evidence. We conclude by discussing open questions on the connections between algorithm design, statistical inference, and experimental replicability.
@article{replicableBandits2025, title = {Replicable Bandits for Digital Health Interventions}, author = {Zhang, Kelly W. and Closser, Nowell and Trella, Anna L. and Murphy, Susan A.}, journal = {Statistical Science}, year = {2025}, } - Bandits/RLContextual Thompson Sampling via Generation of Missing DataKelly W. Zhang, Tiffany (Tianhui) Cai, Hongseok Namkoong, and Daniel RussoAdvances in Neural Information Processing Systems (NeurIPS), 2025
We introduce a framework for Thompson sampling contextual bandit algorithms, in which the algorithm’s ability to quantify uncertainty and make decisions depends on the quality of a generative model that is learned offline. Instead of viewing uncertainty in the environment as arising from unobservable latent parameters, our algorithm treats uncertainty as stemming from missing, but potentially observable, future outcomes. If these future outcomes were all observed, one could simply make decisions using an "oracle" policy fit on the complete dataset. Inspired by this conceptualization, at each decision-time, our algorithm uses a generative model to probabilistically impute missing future outcomes, fits a policy using the imputed complete dataset, and uses that policy to select the next action. We formally show that this algorithm is a generative formulation of Thompson Sampling and prove a state-of-the-art regret bound for it. Notably, our regret bound i) depends on the probabilistic generative model only through the quality of its offline prediction loss, and ii) applies to any method of fitting the "oracle" policy, which easily allows one to adapt Thompson sampling to decision-making settings with fairness and/or resource constraints.
@article{psarContext2025, title = {Contextual Thompson Sampling via Generation of Missing Data}, author = {Zhang, Kelly W. and Cai, Tiffany (Tianhui) and Namkoong, Hongseok and Russo, Daniel}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2025}, } - Health AIWeight Loss After Obesity Disrupts Cognitive Flexibility Through Reinforcement Learning StrategiesYufan Li, Reema Sharma, Abigail Usiyevich, Xiwen Shen, Kelly W. Zhang, Koulik Khamaru, and Bridget A. Matikainen-AnkneyObesity, 2025
Despite successful weight loss, many individuals with obesity regain weight, yet cognitive factors in the weight loss state remain unclear. Here, we tested whether obesity induces deficits in cognitive flexibility, a core component of reinforcement learning (RL), after body weight normalizes.
@article{obesityRL2025, title = {Weight Loss After Obesity Disrupts Cognitive Flexibility Through Reinforcement Learning Strategies}, author = {Li, Yufan and Sharma, Reema and Usiyevich, Abigail and Shen, Xiwen and Zhang, Kelly W. and Khamaru, Koulik and Matikainen-Ankney, Bridget A.}, journal = {Obesity}, year = {2025}, } - Bandits/RLA Deployed Online Reinforcement Learning Algorithm In An Oral Health Clinical TrialAnna L Trella, Kelly W. Zhang, Hinal Jajal, Inbal Nahum-Shani, Vivek Shetty, Finale Doshi-Velez, and Susan A MurphyProceedings of the AAAI Conference on Artificial Intelligence, 2025
Dental disease is a prevalent chronic condition associated with substantial financial burden, personal suffering, and increased risk of systemic diseases. Despite widespread recommendations for twice-daily tooth brushing, adherence to recommended oral self-care behaviors remains sub-optimal due to factors such as forgetfulness and disengagement. To address this, we developed Oralytics, a mHealth intervention system designed to complement clinician-delivered preventative care for marginalized individuals at risk for dental disease. Oralytics incorporates an online reinforcement learning algorithm to determine optimal times to deliver intervention prompts that encourage oral self-care behaviors. We have deployed Oralytics in a registered clinical trial. The deployment required careful design to manage challenges specific to the clinical trials setting in the U.S. In this paper, we (1) highlight key design decisions of the RL algorithm that address these challenges and (2) conduct a re-sampling analysis to evaluate algorithm design decisions. A second phase (randomized control trial) of Oralytics is planned to start in spring 2025.
@article{trella2025monitoring, title = {A Deployed Online Reinforcement Learning Algorithm In An Oral Health Clinical Trial}, author = {Trella, Anna L and Zhang, Kelly W. and Jajal, Hinal and Nahum-Shani, Inbal and Shetty, Vivek and Doshi-Velez, Finale and Murphy, Susan A}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, year = {2025}, } - Bandits/RLActive Exploration via Autoregressive Generation of Missing DataTiffany (Tianhui) Cai, Hongseok Namkoong, Daniel Russo, and Kelly W. ZhangWorking paper; Selected for presentation at the Econometric Society Interdisciplinary Frontiers: Economics and AI+ML conference, 2024
We pose uncertainty quantification and exploration in online decision-making as a problem of training and generation from an autoregressive sequence model, an area experiencing rapid innovation. Our approach rests on viewing uncertainty as arising from missing future outcomes that would be revealed through appropriate action choices, rather than from unobservable latent parameters of the environment. This reformulation aligns naturally with modern machine learning capabilities: we can i) train generative models through next-outcome prediction rather than fit explicit priors, ii) assess uncertainty through autoregressive generation rather than parameter sampling, and iii) adapt to new information through in-context learning rather than explicit posterior updating. To showcase these ideas, we formulate a challenging meta-bandit problem where effective performance requires leveraging unstructured prior information (like text features) while exploring judiciously to resolve key remaining uncertainties. We validate our approach through both theory and experiments. Our theory establishes a reduction, showing success at offline next-outcome prediction translates to reliable online uncertainty quantification and decision-making, even with strategically collected data. Semi-synthetic experiments show our insights bear out in a news-article recommendation task, where article text can be leveraged to minimize exploration.
@article{psar2024, title = {Active Exploration via Autoregressive Generation of Missing Data}, author = {Cai, Tiffany (Tianhui) and Namkoong, Hongseok and Russo, Daniel and Zhang, Kelly W.}, journal = {Working paper; Selected for presentation at the Econometric Society Interdisciplinary Frontiers: Economics and AI+ML conference}, year = {2024}, } - Bandits/RLOralytics Reinforcement Learning AlgorithmAnna L Trella, Kelly W. Zhang, Stephanie M Carpenter, David Elashoff, Zara M Greer, Inbal Nahum-Shani, Dennis Ruenger, Vivek Shetty, Finale Doshi-Velez, and Susan A MurphyTechnical report, 2024
Dental disease is still one of the most common chronic diseases in the United States. While dental disease is preventable through healthy oral self-care behaviors (OSCB), this basic behavior is not consistently practiced. We have developed Oralytics, an online, reinforcement learning (RL) algorithm that optimizes the delivery of personalized intervention prompts to improve OSCB. In this paper, we offer a full overview of algorithm design decisions made using prior data, domain expertise, and experiments in a simulation test bed. The finalized RL algorithm was deployed in the Oralytics clinical trial, conducted from fall 2023 to summer 2024.
@article{oralytics2024, title = {Oralytics Reinforcement Learning Algorithm}, author = {Trella, Anna L and Zhang, Kelly W. and Carpenter, Stephanie M and Elashoff, David and Greer, Zara M and Nahum-Shani, Inbal and Ruenger, Dennis and Shetty, Vivek and Doshi-Velez, Finale and Murphy, Susan A}, journal = {Technical report}, year = {2024}, } - Bandits/RLMonitoring Fidelity of Online Reinforcement Learning Algorithms in Clinical TrialsAnna L Trella, Kelly W. Zhang, Inbal Nahum-Shani, Vivek Shetty, Iris Yan, Finale Doshi-Velez, and Susan A MurphyWorking paper, 2024
Online reinforcement learning (RL) algorithms offer great potential for personalizing treatment for participants in clinical trials. However, deploying an online, autonomous algorithm in the high-stakes healthcare setting makes quality control and data quality especially difficult to achieve. This paper proposes algorithm fidelity as a critical requirement for deploying online RL algorithms in clinical trials. It emphasizes the responsibility of the algorithm to (1) safeguard participants and (2) preserve the scientific utility of the data for post-trial analyses. We also present a framework for pre-deployment planning and real-time monitoring to help algorithm developers and clinical researchers ensure algorithm fidelity. To illustrate our framework’s practical application, we present real-world examples from the Oralytics clinical trial. Since Spring 2023, this trial successfully deployed an autonomous, online RL algorithm to personalize behavioral interventions for participants at risk for dental disease.
@article{trella2024monitoring, title = {Monitoring Fidelity of Online Reinforcement Learning Algorithms in Clinical Trials}, author = {Trella, Anna L and Zhang, Kelly W. and Nahum-Shani, Inbal and Shetty, Vivek and Yan, Iris and Doshi-Velez, Finale and Murphy, Susan A}, journal = {Working paper}, year = {2024}, } - Bandits/RLThe Fallacy of Minimizing Local Regret in the Sequential Task SettingZiping Xu, Kelly W. Zhang, and Susan MurphyWorking paper, 2024
In the realm of Reinforcement Learning (RL), online RL is often conceptualized as an optimization problem, where an algorithm interacts with an unknown environment to minimize cumulative regret. In a stationary setting, strong theoretical guarantees, like a sublinear (√T) regret bound, can be obtained, which typically implies the convergence to an optimal policy and the cessation of exploration. However, these theoretical setups often oversimplify the complexities encountered in real-world RL implementations, where tasks arrive sequentially with substantial changes between tasks and the algorithm may not be allowed to adaptively learn within certain tasks. We study the changes beyond the outcome distributions, encompassing changes in the reward designs (mappings from outcomes to rewards) and the permissible policy spaces. Our results reveal the fallacy of myopically minimizing regret within each task: obtaining optimal regret rates in the early tasks may lead to worse rates in the subsequent ones, even when the outcome distributions stay the same. To realize the optimal cumulative regret bound across all the tasks, the algorithm has to overly explore in the earlier tasks. This theoretical insight is practically significant, suggesting that due to unanticipated changes (e.g., rapid technological development or human-in-the-loop involvement) between tasks, the algorithm needs to explore more than it would in the usual stationary setting within each task. Such implication resonates with the common practice of using clipped policies in mobile health clinical trials and maintaining a fixed rate of ϵ-greedy exploration in robotic learning.
@article{xu2024fallacy, title = {The Fallacy of Minimizing Local Regret in the Sequential Task Setting}, author = {Xu, Ziping and Zhang, Kelly W. and Murphy, Susan}, journal = {Working paper}, year = {2024}, } - Bandits/RLDid we personalize? assessing personalization by an online reinforcement learning algorithm using resamplingSusobhan Ghosh*, Raphael Kim*, Prasidh Chhabria, Raaz Dwivedi, Predrag Klasnja, Peng Liao, Kelly W. Zhang, and Susan MurphyMachine Learning (Special Issue on Reinforcement Learning for Real Life), 2024
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user’s context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user’s historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an “optimized” intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
@article{ghosh2024did, title = {Did we personalize? assessing personalization by an online reinforcement learning algorithm using resampling}, author = {Ghosh, Susobhan and Kim, Raphael and Chhabria, Prasidh and Dwivedi, Raaz and Klasnja, Predrag and Liao, Peng and Zhang, Kelly W. and Murphy, Susan}, journal = {Machine Learning (Special Issue on Reinforcement Learning for Real Life)}, pages = {1--37}, year = {2024}, publisher = {Springer} } - Health AIA mobile health intervention for emerging adults with regular cannabis use: A micro-randomized pilot trial design protocolLara N. Coughlin, Maya Campbell, Tiffany Wheeler, Chavez Rodriguez, Autumn Florimbio, Susobhan Ghosh, Yongyi Guo, Pei-Yao Hung, Kelly W. Zhang, Lauren Zimmerman, Erin Bonar, Maureen Walton, Susan Murphy, and Inbal Nahum-ShaniContemporary Clinical Trials, 2024
Background: Emerging adult (EA) cannabis use is associated with increased risk for health consequences. Just-in-time adaptive interventions (JITAIs) provide potential for preventing the escalation and consequences of cannabis use. Powered by mobile devices, JITAIs use decision rules that take the person’s state and context as input, and output a recommended intervention (e.g., alternative activities, coping strategies). The mHealth literature on JITAIs is nascent, with additional research needed to identify what intervention content to deliver when and to whom. Methods: Herein we describe the protocol for a pilot study testing the feasibility and acceptability of a micro-randomized trial for optimizing MiWaves mobile intervention app for EAs (ages 18-25; target N = 120) with regular cannabis use (≥3 times per week). Micro-randomizations will be determined by a reinforcement learning algorithm that continually learns and improves the decision rules as participants experience the intervention. MiWaves will prompt participants to complete an in-app twice-daily survey over 30 days and participants will be micro-randomized twice daily to either: no message or a message [1 of 6 types varying in length (short, long) and interaction type (acknowledge message, acknowledge message + click additional resources, acknowledge message + fill in the blank/select an option)]. Participants recruited via social media will download the MiWaves app, and complete screening, baseline, weekly, post-intervention, and 2-month follow-up assessments. Primary outcomes include feasibility and acceptability, with additional exploratory behavioral outcomes. Conclusion: This study represents a critical first step in developing an effective mHealth intervention for reducing cannabis use and associated harms in EAs.
@article{nahum2024cannibis, title = {A mobile health intervention for emerging adults with regular cannabis use: A micro-randomized pilot trial design protocol}, author = {Coughlin, Lara N. and Campbell, Maya and Wheeler, Tiffany and Rodriguez, Chavez and Florimbio, Autumn and Ghosh, Susobhan and Guo, Yongyi and Hung, Pei-Yao and Zhang, Kelly W. and Zimmerman, Lauren and Bonar, Erin and Walton, Maureen and Murphy, Susan and Nahum-Shani, Inbal}, journal = {Contemporary Clinical Trials}, publisher = {Elsevier}, pubmed = {https://pubmed.ncbi.nlm.nih.gov/39159806/}, year = {2024} } - Health AIOptimizing an adaptive digital oral health intervention for promoting oral self-care behaviors: Micro-randomized trial protocolInbal Nahum-Shani, Zara M Greer, Anna L Trella, Kelly W. Zhang, Stephanie M Carpenter, Dennis Ruenger, David Elashoff, Susan A Murphy, and Vivek ShettyContemporary Clinical Trials, 2024
Dental disease continues to be one of the most prevalent chronic diseases in the United States. Although oral self-care behaviors (OSCB), involving systematic twice-a-day tooth brushing, can prevent dental disease, this basic behavior is not sufficiently practiced. Recent advances in digital technology offer tremendous potential for promoting OSCB by delivering Just-In-Time Adaptive Interventions (JITAIs)- interventions that leverage dynamic information about the person’s state and context to effectively prompt them to engage in a desired behavior in real-time, real-world settings. However, limited research attention has been given to systematically investigating how to best prompt individuals to engage in OSCB in daily life, and under what conditions prompting would be most beneficial. This paper describes the protocol for a Micro-Randomized Trial (MRT) to inform the development of a JITAI for promoting ideal OSCB, namely, brushing twice daily, for two minutes each time, in all four dental quadrants (i.e., 2x2x4). Sensors within an electric toothbrush (eBrush) will be used to track OSCB and a matching mobile app (Oralytics) will deliver on-demand feedback and educational information. The MRT will micro-randomize participants twice daily (morning and evening) to either (a) a prompt (push notification) containing one of several theoretically grounded engagement strategies or (b) no prompt. The goal is to investigate whether, what type of, and under what conditions prompting increases engagement in ideal OSCB. The results will build the empirical foundation necessary to develop an optimized JITAI that will be evaluated relative to a suitable control in a future randomized controlled trial.
@article{nahum2024optimizing, title = {Optimizing an adaptive digital oral health intervention for promoting oral self-care behaviors: Micro-randomized trial protocol}, author = {Nahum-Shani, Inbal and Greer, Zara M and Trella, Anna L and Zhang, Kelly W. and Carpenter, Stephanie M and Ruenger, Dennis and Elashoff, David and Murphy, Susan A and Shetty, Vivek}, journal = {Contemporary Clinical Trials}, volume = {139}, pages = {107464}, year = {2024}, publisher = {Elsevier}, pubmed = {https://pubmed.ncbi.nlm.nih.gov/38307224/}, clinicaltrials.gov = {https://clinicaltrials.gov/study/NCT05624489} } - Statistical InferenceStatistical Inference for Adaptive ExperimentationKelly W. ZhangThesis, 2023
Online reinforcement learning (RL) algorithms are a very promising tool for personalizing decision-making for digital interventions, e.g., in mobile health, online education, and public policy. Online RL algorithms are increasingly being used in these applications since they are able to use previously collected data to continually learn and improve future decision-making. After deploying online RL algorithms though, it is critical to be able to answer scientific questions like: Did one type of teaching strategy lead to better student outcomes? In which contexts is a digital health intervention effective? The answers to these questions inform decisions about whether to roll out or how to improve a given intervention. Constructing confidence intervals for treatment effects using normal approximations is a natural approach to address these questions. However, classical statistical inference approaches for i.i.d. data fail to provide valid confidence intervals on data collected with online RL algorithms. Since online RL algorithms use previously collected data to inform future treatment decisions, they induce dependence in the collected data. This induced dependence can cause standard statistical inference approaches for i.i.d. data to be invalid on this data type. This thesis provides an understanding of the reasons behind the failure of classical methods in these settings. Moreover, we introduce a variety of alternative statistical inference approaches that are applicable to data collected by online RL algorithms.
@article{zhang2023thesis, title = {Statistical Inference for Adaptive Experimentation}, author = {Zhang, Kelly W.}, journal = {Thesis}, year = {2023} } - Bandits/RLReward design for an online reinforcement learning algorithm supporting oral self-careAnna L Trella, Kelly W. Zhang, Inbal Nahum-Shani, Vivek Shetty, Finale Doshi-Velez, and Susan A MurphyProceedings of the AAAI Conference on Artificial Intelligence, 2023
Dental disease is one of the most common chronic diseases despite being largely preventable. However, professional advice on optimal oral hygiene practices is often forgotten or abandoned by patients. Therefore patients may benefit from timely and personalized encouragement to engage in oral self-care behaviors. In this paper, we develop an online reinforcement learning (RL) algorithm for use in optimizing the delivery of mobile-based prompts to encourage oral hygiene behaviors. One of the main challenges in developing such an algorithm is ensuring that the algorithm considers the impact of the current action on the effectiveness of future actions (i.e., delayed effects), especially when the algorithm has been made simple in order to run stably and autonomously in a constrained, real-world setting (i.e., highly noisy, sparse data). We address this challenge by designing a quality reward which maximizes the desired health outcome (i.e., high-quality brushing) while minimizing user burden. We also highlight a procedure for optimizing the hyperparameters of the reward by building a simulation environment test bed and evaluating candidates using the test bed. The RL algorithm discussed in this paper will be deployed in Oralytics, an oral self-care app that provides behavioral strategies to boost patient engagement in oral hygiene practices.
@article{trella2023reward, title = {Reward design for an online reinforcement learning algorithm supporting oral self-care}, author = {Trella, Anna L and Zhang, Kelly W. and Nahum-Shani, Inbal and Shetty, Vivek and Doshi-Velez, Finale and Murphy, Susan A}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {37}, number = {13}, pages = {15724--15730}, year = {2023} } - Statistical InferenceStatistical Inference after Adaptive Sampling for Longitudinal DataKelly W. Zhang, Lucas Janson, and Susan A MurphyWorking paper, 2023
Online reinforcement learning and other adaptive sampling algorithms are increasingly used in digital intervention experiments to optimize treatment delivery for users over time. In this work, we focus on longitudinal user data collected by a large class of adaptive sampling algorithms that are designed to optimize treatment decisions online using accruing data from multiple users. Combining or "pooling" data across users allows adaptive sampling algorithms to potentially learn faster. However, by pooling, these algorithms induce dependence between the sampled user data trajectories; we show that this can cause standard variance estimators for i.i.d. data to underestimate the true variance of common estimators on this data type. We develop novel methods to perform a variety of statistical analyses on such adaptively sampled data via Z-estimation. Specifically, we introduce the \textitadaptive sandwich variance estimator, a corrected sandwich estimator that leads to consistent variance estimates under adaptive sampling. Additionally, to prove our results we develop novel theoretical tools for empirical processes on non-i.i.d., adaptively sampled longitudinal data which may be of independent interest. This work is motivated by our efforts in designing experiments in which online reinforcement learning algorithms optimize treatment decisions, yet statistical inference is essential for conducting analyses after experiments conclude.
@article{zhang2023statistical, title = {Statistical Inference after Adaptive Sampling for Longitudinal Data}, author = {Zhang, Kelly W. and Janson, Lucas and Murphy, Susan A}, journal = {Working paper}, year = {2023}, } - Bandits/RLDesigning Reinforcement Learning Algorithms for Digital Interventions: Pre-Implementation GuidelinesAnna L. Trella, Kelly W. Zhang, Inbal Nahum-Shani, Vivek Shetty, Finale Doshi-Velez, and Susan A. MurphyAlgorithms (Special Issue Algorithms in Decision Support Systems); Preliminary version at RLDM 2022 (Multi-disciplinary Conference on RL and Decision Making); selected for an oral, 2022
Online reinforcement learning (RL) algorithms are increasingly used to personalize digital interventions in the fields of mobile health and online education. Common challenges in designing and testing an RL algorithm in these settings include ensuring the RL algorithm can learn and run stably under real-time constraints, and accounting for the complexity of the environment, e.g., a lack of accurate mechanistic models for the user dynamics. To guide how one can tackle these challenges, we extend the PCS (predictability, computability, stability) framework, a data science framework that incorporates best practices from machine learning and statistics in supervised learning to the design of RL algorithms for the digital interventions setting. Furthermore, we provide guidelines on how to design simulation environments, a crucial tool for evaluating RL candidate algorithms using the PCS framework. We show how we used the PCS framework to design an RL algorithm for Oralytics, a mobile health study aiming to improve users’ tooth-brushing behaviors through the personalized delivery of intervention messages. Oralytics will go into the field in late 2022.
@article{trella2022designing, author = {Trella, Anna L. and Zhang, Kelly W. and Nahum-Shani, Inbal and Shetty, Vivek and Doshi-Velez, Finale and Murphy, Susan A.}, title = {Designing Reinforcement Learning Algorithms for Digital Interventions: Pre-Implementation Guidelines}, journal = {Algorithms (Special Issue Algorithms in Decision Support Systems); Preliminary version at RLDM 2022 (Multi-disciplinary Conference on RL and Decision Making); selected for an oral}, volume = {15}, year = {2022}, number = {8}, issn = {1999-4893}, } - Statistical InferenceStatistical Inference with M-Estimators on Adaptively Collected DataKelly W. Zhang, Lucas Janson, and Susan MurphyAdvances in Neural Information Processing Systems (NeurIPS), 2021
Bandit algorithms are increasingly used in real-world sequential decision-making problems. Associated with this is an increased desire to be able to use the resulting datasets to answer scientific questions like: Did one type of ad lead to more purchases? In which contexts is a mobile health intervention effective? However, classical statistical approaches fail to provide valid confidence intervals when used with data collected with bandit algorithms. Alternative methods have recently been developed for simple models (e.g., comparison of means). Yet there is a lack of general methods for conducting statistical inference using more complex models on data collected with (contextual) bandit algorithms; for example, current methods cannot be used for valid inference on parameters in a logistic regression model for a binary reward. In this work, we develop theory justifying the use of M-estimators – which includes estimators based on empirical risk minimization as well as maximum likelihood – on data collected with adaptive algorithms, including (contextual) bandit algorithms. Specifically, we show that M-estimators, modified with particular adaptive weights, can be used to construct asymptotically valid confidence regions for a variety of inferential targets.
@article{zhang2021mestimator, author = {Zhang, Kelly W. and Janson, Lucas and Murphy, Susan}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, editor = {Ranzato, M. and Beygelzimer, A. and Dauphin, Y. and Liang, P.S. and Vaughan, J. Wortman}, pages = {7460--7471}, title = {Statistical Inference with M-Estimators on Adaptively Collected Data}, volume = {34}, year = {2021}, } - Statistical InferenceInference for Batched BanditsKelly W. Zhang, Lucas Janson, and Susan MurphyAdvances in Neural Information Processing Systems (NeurIPS), 2020
As bandit algorithms are increasingly utilized in scientific studies and industrial applications, there is an associated increasing need for reliable inference methods based on the resulting adaptively-collected data. In this work, we develop methods for inference on data collected in batches using a bandit algorithm. We first prove that the ordinary least squares estimator (OLS), which is asymptotically normal on independently sampled data, is not asymptotically normal on data collected using standard bandit algorithms when there is no unique optimal arm. This asymptotic non-normality result implies that the naive assumption that the OLS estimator is approximately normal can lead to Type-1 error inflation and confidence intervals with below-nominal coverage probabilities. Second, we introduce the Batched OLS estimator (BOLS) that we prove is (1) asymptotically normal on data collected from both multi-arm and contextual bandits and (2) robust to non-stationarity in the baseline reward.
@article{zhang2020inference, author = {Zhang, Kelly W. and Janson, Lucas and Murphy, Susan}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, editor = {Larochelle, H. and Ranzato, M. and Hadsell, R. and Balcan, M.F. and Lin, H.}, pages = {9818--9829}, title = {Inference for Batched Bandits}, volume = {33}, year = {2020}, } - Bandits/RLA bayesian approach to learning bandit structure in markov decision processesKelly W. Zhang, Omer Gottesman, and Finale Doshi-VelezChallenges of Real-World Reinforcement Learning, 2020
In the reinforcement learning literature, there are many algorithms developed for either Contextual Bandit (CB) or Markov Decision Processes (MDP) environments. However, when deploying reinforcement learning algorithms in the real world, even with domain expertise, it is often difficult to know whether it is appropriate to treat a sequential decision making problem as a CB or an MDP. In other words, do actions affect future states, or only the immediate rewards? Making the wrong assumption regarding the nature of the environment can lead to inefficient learning, or even prevent the algorithm from ever learning an optimal policy, even with infinite data. In this work we develop an online algorithm that uses a Bayesian hypothesis testing approach to learn the nature of the environment. Our algorithm allows practitioners to incorporate prior knowledge about whether the environment is that of a CB or an MDP, and effectively interpolate between classical CB and MDP-based algorithms to mitigate against the effects of misspecifying the environment. We perform simulations and demonstrate that in CB settings our algorithm achieves lower regret than MDP-based algorithms, while in non-bandit MDP settings our algorithm is able to learn the optimal policy, often achieving comparable regret to MDP-based algorithms.
@article{zhang2022bayesian, title = {A bayesian approach to learning bandit structure in markov decision processes}, author = {Zhang, Kelly W. and Gottesman, Omer and Doshi-Velez, Finale}, journal = {Challenges of Real-World Reinforcement Learning}, year = {2020}, } - MLLanguage modeling teaches you more syntax than translation does: Lessons learned through auxiliary task analysisKelly W. Zhang and Samuel R BowmanBlackboxNLP, 2018
Recent work using auxiliary prediction task classifiers to investigate the properties of LSTM representations has begun to shed light on why pretrained representations, like ELMo (Peters et al., 2018) and CoVe (McCann et al., 2017), are so beneficial for neural language understanding models. We still, though, do not yet have a clear understanding of how the choice of pretraining objective affects the type of linguistic information that models learn. With this in mind, we compare four objectives—language modeling, translation, skip-thought, and autoencoding—on their ability to induce syntactic and part-of-speech information. We make a fair comparison between the tasks by holding constant the quantity and genre of the training data, as well as the LSTM architecture. We find that representations from language models consistently perform best on our syntactic auxiliary prediction tasks, even when trained on relatively small amounts of data. These results suggest that language modeling may be the best data-rich pretraining task for transfer learning applications requiring syntactic information. We also find that the representations from randomly-initialized, frozen LSTMs perform strikingly well on our syntactic auxiliary tasks, but this effect disappears when the amount of training data for the auxiliary tasks is reduced.
@article{zhang2018language, title = {Language modeling teaches you more syntax than translation does: Lessons learned through auxiliary task analysis}, author = {Zhang, Kelly W. and Bowman, Samuel R}, journal = {BlackboxNLP}, year = {2018}, } - MLAdversarially Regularized AutoencodersJunbo (Jake) Zhao*, Yoon Kim*, Kelly W. Zhang, Alexander Rush, and Yann LeCunInternational Conference on Machine Learning (ICML), 2018
Deep latent variable models, trained using variational autoencoders or generative adversarial networks, are now a key technique for representation learning of continuous structures. However, applying similar methods to discrete structures, such as text sequences or discretized images, has proven to be more challenging. In this work, we propose a more flexible method for training deep latent variable models of discrete structures. Our approach is based on the recently proposed Wasserstein Autoencoder (WAE) which formalizes adversarial autoencoders as an optimal transport problem. We first extend this framework to model discrete sequences, and then further explore different learned priors targeting a controllable representation. Unlike many other latent variable generative models for text, this adversarially regularized autoencoder (ARAE) allows us to generate fluent textual outputs as well as perform manipulations in the latent space to induce change in the output space. Finally we show that the latent representation can be trained to perform unaligned textual style transfer, giving improvements both in automatic measures and human evaluation.
@article{pmlr-v80-zhao18b, title = {Adversarially Regularized Autoencoders}, author = {Zhao, Junbo (Jake) and Kim, Yoon and Zhang, Kelly W. and Rush, Alexander and LeCun, Yann}, journal = {International Conference on Machine Learning (ICML)}, year = {2018}, series = {Proceedings of Machine Learning Research}, }